¿Tienes una DB HANA y tu app es lenta? Sospecha porque
Introducción
Hoy me voy a poner serio. Creo que a estas alturas todos tenemos la idea de que HANA es una base de datos muy rápida pero ¿gracias a ello nos podemos despreocupar del rendimiento? Ya os digo la respuesta, NO.
Una conversación que oigo de vez en cuando y seguro os sonará es:
- Me preocupa un poco la gran cantidad de registros que tenemos, ¿no sera un poco lenta la aplicación?
- NO! Si tenemos una base de datos HANA
- Ya pero son muchísimos registros
- No pasa nada… lo guardamos en columnas y no en filas que es mas eficiente.
Si te identificas con esta preocupación, dos cosas, la primera, Bienvenido! esta entrada te puede interesar. La segunda es… pregúntale a tu interlocutor como funciona esto de las tablas en HANA para asegurarte que entiende bien como funcionan.
Todo en memoria (sin problema)
SAP ha hecho mucha publicidad para que sepamos que es una base de datos en memoria RAM que se aprovecha de las capacidades de multiprocesador para acceder a los datos de manera más rápida.
Por lo que nos podemos aprovechar de esta característica sin mas, nuestros selects serán mas rápidas.
Columnas VS Filas (Problema conceptual)
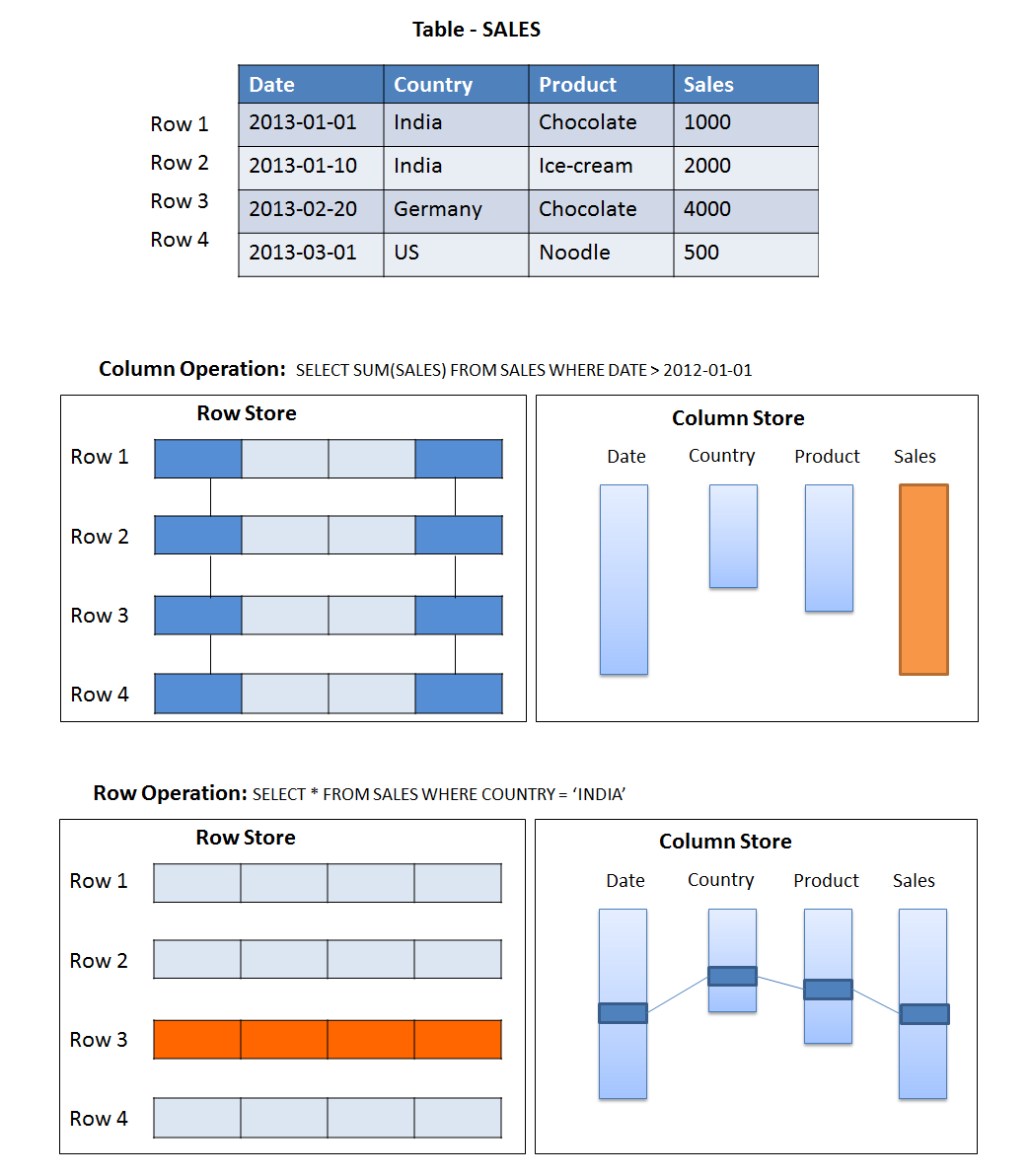
Este es el motivo de este post. Y es que uno de los falsos mitos de HANA es pensar que siempre se deben utilizar las tablas tipo columna sin criterio pensando que serán mas rápidas.
El gran avance de HANA es la utilización de bases de datos con indices por columnas que permiten comprimir los datos.
Filas
Pasemos al ejemplo practico partiendo de una tabla por filas de toda la vida

Las tablas tipo fila guardan los datos reservando toda la fila para esa entrada, por lo que se malbarata ciertos puntos de memoria, pero nos permite obtener y tratar los datos de filas de manera rápida. Por lo que se recomienda el uso cuando nuestra aplicación utiliza filas para leer y modificar datos de manera constante. También se recomienda cuando el uso de estas tablas no requiere agregación, en el caso anterior si no necesitamos datos agrupados por la columna B o C.
Columna
Vamos a pasar la tabla a tipo columna. Aunque en este caso no esta representada de manera fiel, se han comprimido los datos duplicados y en la base de datos Hana estarían ordenados para que la búsqueda sea mas eficiente..

Este tipo de tablas son eficientes cuando los selects requieren un numero de columnas limitado. También es recomendable para tablas con muchas columnas que requerirán agregación de datos (menor espacio en base de datos). Pero pueden penalizar en el caso de querer realizar muchas actualizaciones (o inserts) en la base de datos.
CDS (Pueden ser un cuello de botella)
Una vez superado el problema de que base de datos usar. Es el momento de las CDS. Por naturaleza creemos que por usar CDS ya seremos mas eficientes. Pero eso no es cierto al 100%
Los Core Data Services, son mas que unas vistas ultra rápidas. Permiten la definición de tablas ( DDL ), contiene servicios de indexado, cache, etc que permiten eficientar las búsquedas ( QL ) y añadir permisos de utilización ( DCL ).
Por lo que se recomienda reducir la complejidad, a mas complejas mas lentas. Me refiero a no unir muchas tablas entre si.
Ayudar al interprete de CDS utilizando @ObjectModel.usageType para que entienda como tratar el cache de datos.

Hasta aquí la entrada de hoy. Como cualquier máquina de alto rendimiento hay que conocer la filosofía y tecnología detrás de la base de datos HANA para que el rendimiento no nos caiga en picado.
En algunas ocasiones escuchareis cosas como:
- Hemos quitado todas las CDS porque no son eficientes
- La base de datos HANA funciona peor que las anteriores
En vuestras manos esta crear con cabeza vuestras bases de datos y consultas para poder acceder de manera eficiente a los datos.
Por último, Suscribete y comparte en redes
